Foreword: please note that the code available here is only for demonstration purposes. If you want to be serious, you'll have to make it more robust and integrate it with other code. Also, the description is by no means a definitive reference on the subject, but rather the result of my experimentation. Please report any bug or error you find in the code or otherwise in this article. Thanks.
Link to the source tarball described in the article:
simpletun.
Update 18/07/2010: Thanks to
this post, I've learned that recent versions of
iproute2 can (finally) create tun/tap devices, although the functionality is (still?) blissfully undocumented. Thus, installing tunctl (UML utilities) or OpenVPN just to be able to create tun devices is no longer needed. The following is with
iproute2-2.6.34:
# ip tuntap help
Usage: ip tuntap { add | del } [ dev PHYS_DEV ]
[ mode { tun | tap } ] [ user USER ] [ group GROUP ]
[ one_queue ] [ pi ] [ vnet_hdr ]
Where: USER := { STRING | NUMBER }
GROUP := { STRING | NUMBER }
Tun/tap interfaces are a feature offered by Linux (and probably by other UNIX-like operating systems) that can do userspace networking, that is, allow userspace programs to see raw network traffic (at the ethernet or IP level) and do whatever they like with it. This document attempts to explain how tun/tap interfaces work under Linux, with some sample code to demonstrate their usage.
How it works
Tun/tap interfaces are software-only interfaces, meaning that they exist only in the kernel and, unlike regular network interfaces, they have no physical hardware component (and so there's no physical "wire" connected to them). You can think of a tun/tap interface as a regular network interface that, when the kernel decides that the moment has come to send data "on the wire", instead sends data to some userspace program that is attached to the interface (using a specific procedure, see below). When the program attaches to the tun/tap interface, it gets a special file descriptor, reading from which gives it the data that the interface is sending out. In a similar fashion, the program can write to this special descriptor, and the data (which must be properly formatted, as we'll see) will appear as input to the tun/tap interface. To the kernel, it would look like the tun/tap interface is receiving data "from the wire".
The difference between a tap interface and a tun interface is that a tap interface outputs (and must be given) full ethernet frames, while a tun interface outputs (and must be given) raw IP packets (and no ethernet headers are added by the kernel). Whether an interface functions like a tun interface or like a tap interface is specified with a flag when the interface is created.
The interface can be transient, meaning that it's created, used and destroyed by the same program; when the program terminates, even if it doesn't explicitly destroy the interface, the interfaces ceases to exist. Another option (the one I prefer) is to make the interface persistent; in this case, it is created using a dedicated utility (like tunctl or openvpn --mktun), and then normal programs can attach to it; when they do so, they must connect using the same type (tun or tap) used to originally create the interface, otherwise they will not be able to attach. We'll see how that is done in the code.
Once a tun/tap interface is in place, it can be used just like any other interface, meaning that IP addresses can be assigned, its traffic can be analyzed, firewall rules can be created, routes pointing to it can be established, etc.
With this knowledge, let's try to see how we can use a tun/tap interface and what can be done with it.
Creating the interface
The code to create a brand new interface and to (re)attach to a persistent interface is essentially the same; the difference is that the former must be run by root (well, more precisely, by a user with the CAP_NET_ADMIN capability), while the latter can be run by an ordinary user if certain conditions are met. Let's start with the creation of a new interface.
First, whatever you do, the device /dev/net/tun must be opened read/write. That device is also called the clone device, because it's used as a starting point for the creation of any tun/tap virtual interface. The operation (as with any open() call) returns a file descriptor. But that's not enough to start using it to communicate with the interface.
The next step in creating the interface is issuing a special ioctl() system call, whose arguments are the descriptor obtained in the previous step, the TUNSETIFF constant, and a pointer to a data structure containing the parameters describing the virtual interface (basically, its name and the desired operating mode - tun or tap). As a variation, the name of the virtual interface can be left unspecified, in which case the kernel will pick a name by trying to allocate the "next" device of that kind (for example, if tap2 already exists, the kernel will try to allocate tap3, and so on). All of this must be done by root(or by a user with the CAP_NET_ADMIN capability - I won't repeat that again; assume it applies everywhere I say "must be run by root").
If the ioctl() succeeds, the virtual interface is created and the file descriptor we had is now associated to it, and can be used to communicate.
At this point, two things can happen. The program can start using the interface right away (probably configuring it with at least an IP address before), and, when it's done, terminate and destroy the interface. The other option is to issue a couple of other special ioctl() calls to make the interface persistent, and terminate leaving it in place for other programs to attach to it. This is what programs like tunctl or openvpn --mktun do, for example. These programs usually can also optionally set the ownership of the virtual interface to a non-root user and/or group, so programs running as non-root but with the appropriate privileges can attach to the interface later. We'll come back to this below.
The basic code used to create a virtual interface is shown in the file Documentation/networking/tuntap.txt in the kernel source tree. Modifying it a bit, we can write a barebone function that creates a virtual interface:
#include <linux /if.h>
#include <linux /if_tun.h>
int tun_alloc(char *dev, int flags) {
struct ifreq ifr;
int fd, err;
char *clonedev = "/dev/net/tun";
/* Arguments taken by the function:
*
* char *dev: the name of an interface (or '\0'). MUST have enough
* space to hold the interface name if '\0' is passed
* int flags: interface flags (eg, IFF_TUN etc.)
*/
/* open the clone device */
if( (fd = open(clonedev, O_RDWR)) < 0 ) {
return fd;
}
/* preparation of the struct ifr, of type "struct ifreq" */
memset(&ifr, 0, sizeof(ifr));
ifr.ifr_flags = flags; /* IFF_TUN or IFF_TAP, plus maybe IFF_NO_PI */
if (*dev) {
/* if a device name was specified, put it in the structure; otherwise,
* the kernel will try to allocate the "next" device of the
* specified type */
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
/* try to create the device */
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ) {
close(fd);
return err;
}
/* if the operation was successful, write back the name of the
* interface to the variable "dev", so the caller can know
* it. Note that the caller MUST reserve space in *dev (see calling
* code below) */
strcpy(dev, ifr.ifr_name);
/* this is the special file descriptor that the caller will use to talk
* with the virtual interface */
return fd;
}
The tun_alloc() function takes two parameters:
char *dev contains the name of an interface (for example, tap0, tun2, etc.). Any name can be used, though it's probably better to choose a name that suggests which kind of interface it is. In practice, names like tunX or tapX are usually used. If *dev is '\0', the kernel will try to create the "first" available interface of the requested type (eg, tap0, but if that already exists, tap1, and so on).int flags contains the flags that tell the kernel which kind of interface we want (tun or tap). Basically, it can either take the value IFF_TUN to indicate a TUN device (no ethernet headers in the packets), or IFF_TAP to indicate a TAP device (with ethernet headers in packets).
Additionally, another flag IFF_NO_PI can be ORed with the base value. IFF_NO_PI tells the kernel to not provide packet information. The purpose of IFF_NO_PI is to tell the kernel that packets will be "pure" IP packets, with no added bytes. Otherwise (if IFF_NO_PI is unset), 4 extra bytes are added to the beginning of the packet (2 flag bytes and 2 protocol bytes). IFF_NO_PI need not match between interface creation and reconnection time. Also note that when capturing traffic on the interface with Wireshark, those 4 bytes are never shown.
A program can thus use the following code to create a device:
char tun_name[IFNAMSIZ];
char tap_name[IFNAMSIZ];
char *a_name;
...
strcpy(tun_name, "tun1");
tunfd = tun_alloc(tun_name, IFF_TUN); /* tun interface */
strcpy(tap_name, "tap44");
tapfd = tun_alloc(tap_name, IFF_TAP); /* tap interface */
a_name = malloc(IFNAMSIZ);
a_name[0]='\0';
tapfd = tun_alloc(a_name, IFF_TAP); /* let the kernel pick a name */
At this point, as said before, the program can either use the interface as is for its purposes, or it can set it persistent (and optionally assign ownership to a specific user/group). If it does the former, there's not much more to be said. But if it does the latter, here's what happens.
Two additional ioctl()s are available, which are usually used together. The first syscall can set (or remove) the persistent status on the interface. The second allows assigning ownership of the interface to a regular (non-root) user. Both features are implemented in the programs tunctl (part of UML utilities) and openvpn --mktun (and probably others). Let's examine the tunctl code since it's simpler, keeping in mind that it only creates tap interfaces, as those are what user mode linux uses (code slightly edited and simplified for clarity):
...
/* "delete" is set if the user wants to delete (ie, make nonpersistent)
an existing interface; otherwise, the user is creating a new
interface */
if(delete) {
/* remove persistent status */
if(ioctl(tap_fd, TUNSETPERSIST, 0)< 0){
perror("disabling TUNSETPERSIST");
exit(1);
}
printf("Set '%s' nonpersistent\n", ifr.ifr_name);
}
else {
/* emulate behaviour prior to TUNSETGROUP */
if(owner == -1 && group == -1) {
owner = geteuid();
}
if(owner != -1) {
if(ioctl(tap_fd, TUNSETOWNER, owner)< 0){
perror("TUNSETOWNER");
exit(1);
}
}
if(group != -1) {
if(ioctl(tap_fd, TUNSETGROUP, group)< 0){
perror("TUNSETGROUP");
exit(1);
}
}
if(ioctl(tap_fd, TUNSETPERSIST, 1)< 0){
perror("enabling TUNSETPERSIST");
exit(1);
}
if(brief)
printf("%s\n", ifr.ifr_name);
else {
printf("Set '%s' persistent and owned by", ifr.ifr_name);
if(owner != -1)
printf(" uid %d", owner);
if(group != -1)
printf(" gid %d", group);
printf("\n");
}
}
...
These additional ioctl()s must still be run by root. But what we have now is a persistent interface owned by a specific user, so processes running as that user can successfully attach to it.
As said, it turns out that the code to (re)attach to an existing tun/tap interface is the same as the code used to create it; in other words, tun_alloc() can again be used. When doing so, for it to be successful three things must happen:
- The interface must exist already and be owned by the same user that is attempting to connect (and probably be persistent)
- the user must have read/write permissions on /dev/net/tun
- The flags provided must match those used to create the interface (eg if it was created with IFF_TUN then the same flag must be used when reattaching)
This is possible because the kernel allows the TUNSETIFF ioctl() to succeed if the user issuing it specifies the name of an already existing interface and he is the owner of the interface. In this case, no new interface has to be created, so a regular user can successfully perform the operation.
So this is an attempt to explain what happens when ioctl(TUNSETIFF) is called, and how the kernel differentiates between the request for the allocation of a new interface and the request to connect to an existing interface:
- If a non-existent or no interface name is specified, that means the user is requesting the allocation of a new interface. The kernel thus creates an interface using the given name (or picking the next available name if an empty name was given). This works only if done by root.
- If the name of an existing interface is specified, that means the user wants to connect to a previously allocated interface. This can be done by a normal user, provided that: the user has appropriate rights on the clone device AND is the owner of the interface (set at creation time), AND the specified mode (tun or tap) matches the mode set at creation time.
You can have a look at the code that implements the above steps in the file drivers/net/tun.c in the kernel source; the important functions are tun_attach(), tun_net_init(), tun_set_iff(), tun_chr_ioctl(); this last function also implements the various ioctl()s available, including TUNSETIFF, TUNSETPERSIST, TUNSETOWNER, TUNSETGROUP and others.
In any case, no non-root user is allowed to configure the interface (ie, assign an IP address and bring it up), but this is true of any regular interface too. The usual methods (suid binary wrapper, sudo, etc.) can be used if a non-root user needs to do some operation that requires root privileges.
This is a possible usage scenario (one I use all the time):
- The virtual interfaces are created, made persistent, assigned to an user, and configured by root (for example, by initscripts at boot time, using tunctlor equivalent)
- The regular users can then attach and detach as many times as they wish from virtual interfaces that they own.
- The virtual interfaces are destroyed by root, for example by scripts run at shutdown time, perhaps using tunctl -d or equivalent
Let's try it
After this lengthy but necessary introduction, it's time to do some work with it. So, since this is a normal interface, we can use it as we would another regular interface. For our purposes, there is no difference between tun and tap interfaces; it's the program that creates or attaches to it that must know its type and accordingly expect or write data. Let's create a persistent interface and assign it an IP address:
# openvpn --mktun --dev tun2
Fri Mar 26 10:29:29 2010 TUN/TAP device tun2 opened
Fri Mar 26 10:29:29 2010 Persist state set to: ON
# ip link set tun2 up
# ip addr add 10.0.0.1/24 dev tun2
Let's fire up a network analyzer and look at the traffic:
# tshark -i tun2
Running as user "root" and group "root". This could be dangerous.
Capturing on tun2
# On another console
# ping 10.0.0.1
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.115 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.105 ms
...
Looking at the output of tshark, we see...nothing. There is no traffic going through the interface. This is correct: since we're pinging the interface's IP address, the operating system correctly decides that no packet needs to be sent "on the wire", and the kernel itself is replying to these pings. If you think about it, it's exactly what would happen if you pinged another interface's IP address (for example eth0): no packets would be sent out. This might sound obvious, but could be a source of confusion at first (it was for me).
Knowing that the assignment of a /24 IP address to an interface creates a connected route for the whole range through the interface, let's modify our experiment and force the kernel to actually send something out of the tun interface (NOTE: the following works only with kernels < 2.6.36; later kernels behave differently, as explained in the comments):
# ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
From 10.0.0.1 icmp_seq=2 Destination Host Unreachable
From 10.0.0.1 icmp_seq=3 Destination Host Unreachable
...
# on the tshark console
...
0.000000 10.0.0.1 -> 10.0.0.2 ICMP Echo (ping) request
0.999374 10.0.0.1 -> 10.0.0.2 ICMP Echo (ping) request
1.999055 10.0.0.1 -> 10.0.0.2 ICMP Echo (ping) request
...
Now we're finally seeing something. The kernel sees that the address does not belong to a local interface, and a route for 10.0.0.0/24 exists through the tun2 interface. So it duly sends the packets out tun2. Note the different behavior here between tun and tap interfaces: with a tun interface, the kernel sends out the IP packet (raw, no other headers are present - try analyzing it with tshark or wireshark), while with a tap interface, being ethernet, the kernel would try to ARP for the target IP address:
# pinging 10.0.0.2 now, but through tap2 (tap)
# ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
# on the tshark console
...
0.111858 82:03:d4:07:62:b6 -> Broadcast ARP Who has 10.0.0.2? Tell 10.0.0.1
1.111539 82:03:d4:07:62:b6 -> Broadcast ARP Who has 10.0.0.2? Tell 10.0.0.1
...
Furthermore, with a tap interface the traffic will be composed by full ethernet frames (again, you can check with the network analyzer). Note that the MAC address for a tap interface is autogenerated by the kernel at interface creation time, but can be changed using the SIOCSIFHWADDR ioctl() (look again in drivers/net/tun.c, function tun_chr_ioctl()). Finally, being an ethernet interface, the MTU is set to 1500:
# ip link show dev tap2
7: tap2: mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 500
link/ether 82:03:d4:07:62:b6 brd ff:ff:ff:ff:ff:ff
Of course, so far no program is attached to the interface, so all these outgoing packets are just lost. So let's do a step ahead and write a simple program that attaches to the interface and reads packets sent out by the kernel.
A simple program
We're going to write a program that attaches to a tun interface and reads packets that the kernel sends out that interface. Remember that you can run the program as a normal user if the interface is persistent, provided that you have the necessary permissions on the clone device /dev/net/tun, you are the owner of the interface, and select the right mode (tun or tap) for the interface. The program is actually a skeleton, or rather the start of a skeleton, since we'll only demonstrate how to read from the device, and only explain what the program can do once it gets the data. We assume that the tun_alloc() function we defined earlier is available to the program. Here is the code:
...
/* tunclient.c */
char tun_name[IFNAMSIZ];
/* Connect to the device */
strcpy(tun_name, "tun77");
tun_fd = tun_alloc(tun_name, IFF_TUN | IFF_NO_PI); /* tun interface */
if(tun_fd < 0){
perror("Allocating interface");
exit(1);
}
/* Now read data coming from the kernel */
while(1) {
/* Note that "buffer" should be at least the MTU size of the interface, eg 1500 bytes */
nread = read(tun_fd,buffer,sizeof(buffer));
if(nread < 0) {
perror("Reading from interface");
close(tun_fd);
exit(1);
}
/* Do whatever with the data */
printf("Read %d bytes from device %s\n", nread, tun_name);
}
...
If you configure tun77 as having IP address 10.0.0.1/24 and then run the above program while trying to ping 10.0.0.2 (or any address in 10.0.0.0/24 other than 10.0.0.1, for that matter), you'll read data from the device:
# openvpn --mktun --dev tun77 --user waldner
Fri Mar 26 10:48:12 2010 TUN/TAP device tun77 opened
Fri Mar 26 10:48:12 2010 Persist state set to: ON
# ip link set tun77 up
# ip addr add 10.0.0.1/24 dev tun77
# ping 10.0.0.2
...
# on another console
$ ./tunclient
Read 84 bytes from device tun77
Read 84 bytes from device tun77
...
If you do the math, you'll see where these 84 byetes come from: 20 are for the IP header, 8 for the ICMP header, and 56 are the payload of the ICMP echo message as you can see when you run the ping command:
$ ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
...
Try experimenting with the above program sending various traffic types through the interface (also try using tap), and verify that the size of the data you're reading is correct for the interface type. Each read() returns a full packet (or frame if using tap mode); similarly, if we were to write, we would have to write an entire IP packet (or ethernet frame in tap mode) for each write().
Now what can we do with this data? Well, we could for example emulate the behavior of the target of the traffic we're reading; again, to keep things simple, let's stick with the ping example. We could analyze the received packet, extract the information needed to reply from the IP header, ICMP header and payload, build an IP packet containing an appropriate ICMP echo reply message, and send it back (ie, write it into the descriptor associated with the tun/tap device). This way the originator of the ping will actually receive an answer. Of course you're not limited to ping, so you can implement all kinds of network protocols. In general, this implies parsing the received packet, and act accordingly. If using tap, to correctly build reply frames you would probably need to implement ARP in your code. All of this is exactly what
User Mode Linux does: it attaches a modified Linux kernel running in userspace to a tap interface that exist on the host, and communicates with the host through that. Of course, being a full Linux kernel, it does implement TCP/IP and ethernet. Newer virtualization platforms like
libvirt use tap interfaces extensively to communicate with guests that support them like
qemu/kvm; the interfaces have usually names like
vnet0,
vnet1 etc. and last only as long as the guest they connect to is running, so they're not persistent, but you can see them if you run
ip link show and/or
brctl show while guests are running.
In the same way, you can attach with your own code to the interface and practice network programming and/or ethernet and TCP/IP stack implementation. To get started, you can look at (you guessed it)
drivers/net/tun.c, functions
tun_get_user() and
tun_put_user() to see how the tun driver does that on the kernel side (beware that barely scratches the surface of the complete network packet management in the kernel, which is very complex).
Tunnels
But there's another thing we can do with tun/tap interfaces. We can create
tunnels. We don't need to reimplement TCP/IP; instead, we can write a program to just relay the raw data back and forth to a remote host running the same program, which does the same thing in a specular way. Let's suppose that our program above, in addition to attaching to the tun/tap interface, also establishes a network connection to a remote host, where a similar program (connected to a local tun/tap interface as well) is running in server mode. (Actually the two programs are the same, who is the server and who is the client is decided with a command line switch). Once the two programs are running, traffic can flow in either direction, since the main body of the code will be doing the same thing at both sites. The network connection here is implemented using TCP, but any other mean can be used (ie UDP, or even ICMP!). You can download the full program source code here:
simpletun.
Here is the main loop of the program, where the actual work of moving data back and forth between the tun/tap interface and the network tunnel is performed. For clearness, debug statements have been removed (you can find the full version in the source tarball).
...
/* net_fd is the network file descriptor (to the peer), tap_fd is the
descriptor connected to the tun/tap interface */
/* use select() to handle two descriptors at once */
maxfd = (tap_fd > net_fd)?tap_fd:net_fd;
while(1) {
int ret;
fd_set rd_set;
FD_ZERO(&rd_set);
FD_SET(tap_fd, &rd_set); FD_SET(net_fd, &rd_set);
ret = select(maxfd + 1, &rd_set, NULL, NULL, NULL);
if (ret < 0 && errno == EINTR) {
continue;
}
if (ret < 0) {
perror("select()");
exit(1);
}
if(FD_ISSET(tap_fd, &rd_set)) {
/* data from tun/tap: just read it and write it to the network */
nread = cread(tap_fd, buffer, BUFSIZE);
/* write length + packet */
plength = htons(nread);
nwrite = cwrite(net_fd, (char *)&plength, sizeof(plength));
nwrite = cwrite(net_fd, buffer, nread);
}
if(FD_ISSET(net_fd, &rd_set)) {
/* data from the network: read it, and write it to the tun/tap interface.
* We need to read the length first, and then the packet */
/* Read length */
nread = read_n(net_fd, (char *)&plength, sizeof(plength));
/* read packet */
nread = read_n(net_fd, buffer, ntohs(plength));
/* now buffer[] contains a full packet or frame, write it into the tun/tap interface */
nwrite = cwrite(tap_fd, buffer, nread);
}
}
...
(for the details of the read_n() and cwrite() functions, refer to the source; what they do should be obvious. Yes, the above code is not 100% correct with regard to select(), and makes some naive assumptions like expecting that read_n() and cwrite() do not block. As I said, the code is for demonstration purposes only)
Here is the main logic of the above code:
- The program uses select() to keep both descriptors under control at the same time; if data comes in from either descriptor, it's written out to the other.
- Since the program usese TCP, the receiver will see a single stream of data, which makes recognizing packet boundaries difficult. So when a packet or frame is written to the network, its length is prepended (2 bytes) to the actual packet.
- When data comes in from the tap_fd descriptor, a single read reads a full packet or frame; thus this can directly be written to the network, with its length prepended. Since that length number is a short int, thus longer than one byte, written in "raw" binary format, ntohs()/htons() are used to interoperate between machines with different endianness.
- When data comes in from the network, thanks to the aforementioned trick, we can know how long the next packet is going to be by reading the two-bytes length that precedes it in the stream. When we've read the packet, we write it to the tun/tap interface descriptor, where it will be received by the kernel as coming "from the wire".
So what can you do with such a program? Well, you can create a tunnel! First, create and confgure the necessary tun/tap interfaces on the hosts at both ends of the tunnel, including assigning them an IP address. For this example, I'll assume two tun interfaces: tun11, 192.168.0.1/24 on the local computer, and tun3, 192.168.0.2/24 on the remote computer. simpletun connects the hosts using TCP port 55555 by default (you can change that using the -p command line switch). The remote host will run simpletun in server mode, and the local host will run in client mode. So here we go (the remote server is at 10.2.3.4):
[remote]# openvpn --mktun --dev tun3 --user waldner
Fri Mar 26 11:11:41 2010 TUN/TAP device tun3 opened
Fri Mar 26 11:11:41 2010 Persist state set to: ON
[remote]# ip link set tun3 up
[remote]# ip addr add 192.168.0.2/24 dev tun3
[remote]$ ./simpletun -i tun3 -s
# server blocks waiting for the client to connect
[local]# openvpn --mktun --dev tun11 --user waldner
Fri Mar 26 11:17:37 2010 TUN/TAP device tun11 opened
Fri Mar 26 11:17:37 2010 Persist state set to: ON
[local]# ip link set tun11 up
[local]# ip addr add 192.168.0.1/24 dev tun11
[local]$ ./simpletun -i tun11 -c 10.2.3.4
# nothing happens, but the peers are now connected
[local]$ ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=241 time=42.5 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=241 time=41.3 ms
64 bytes from 192.168.0.2: icmp_seq=3 ttl=241 time=41.4 ms
64 bytes from 192.168.0.2: icmp_seq=4 ttl=241 time=41.0 ms
--- 192.168.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2999ms
rtt min/avg/max/mdev = 41.047/41.599/42.588/0.621 ms
# let's try something more exciting now
[local]$ ssh waldner@192.168.0.2
waldner@192.168.0.2's password:
Linux remote 2.6.22-14-xen #1 SMP Fri Feb 29 16:20:01 GMT 2008 x86_64
Welcome to remote!
[remote]$
When a tunnel like the above is set up, all that can be seen from the outside is just a connection (TCP in this case) between the two peer simpletuns. The "real" data (ie, that exchanged by the high level applications - ping or ssh in the above example) is never exposed directly on the wire (although it IS sent in cleartext, see below). If you enable IP forwarding on a host that is running simpletun, and create the necessary routes on the other host, you can reach remote networks through the tunnel.
Also note that if the virtual interfaces involved are of the tap kind, it is possible to transparently bridge two geographically distant ethernet LANs, so that the devices think that they are all on the same layer 2 network. To do this, it's necessary to bridge, on the gateways (ie, the hosts that run simpletun or another tunneling software that uses tap interfaces), the local LAN interface and the virtual tap interface together. This way, frames received from the LAN are also sent to the tap interface (because of the bridge), where the tunneling application reads them and send them to the remote peer; there, another bridge will ensure that frames so received are forwarded to the remote LAN. The same thing will happen in the opposite direction. Since we are passing ethernet frames between the two LANs, the two LANs are effectively bridged together. This means that you can have 10 machines in London (for instance) and 50 in Berlin, and you can create a 60-computer ethernet network using addresses from the 192.168.1.0/24 subnet (or any subnet address you want, as long as it can accommodate at least 60 host addresses). However, do NOT use simpletun if you want to set up something like that!
Extensions and improvements
simpletun is very simple and simplistic, and can be extended in a number of ways. First of all, new ways of connecting to the peer can be added. For example, UDP connectivity could be implemented, or, if you're brave, ICMP (perhaps also over IPv6). Second, data is currently passed in cleartext over the network connection. But when the data is in the program's buffer it could be changed somehow before being transmitted, for example it could be encrypted (and similarly decrypted at the other end).
However, for the purpose of this tutorial, the limited version of the program should already give you an idea of how tunnelling using tun/tap works. While
simpletun is a simple demonstration, this is the way many popular programs that use tun/tap interfaces work, like
OpenVPN,
vtun, or
Openssh's
VPN feature.
Finally, it's worth noting that if the tunnel connection is over TCP, we can have a situation where we're running the so-called "tcp over tcp"; for more information see
"Why tcp over tcp is a bad idea". Note that applications like OpenVPN use UDP by default for this very reason, and using TCP is well-known for reducing performance (although in some cases it's the only option).




 关于导入Magnet成功却从未有速度,且不显示文件名的,可能存在的问题,缺少dht.dat,参考下文中的dht.dat的处理方法 ###配置 密码:
关于导入Magnet成功却从未有速度,且不显示文件名的,可能存在的问题,缺少dht.dat,参考下文中的dht.dat的处理方法 ###配置 密码:
 黄色的就是转换符号,未用到任何数据库,没有转换完成通知,调用时间根据你的设置的PHP脚本运行时间为止。 在线转码,请 php.ini中修改:
黄色的就是转换符号,未用到任何数据库,没有转换完成通知,调用时间根据你的设置的PHP脚本运行时间为止。 在线转码,请 php.ini中修改:














It is important to note that this frames contain the data originally written from program A, but it's buried into the payload; outside it will have headers (ethernet, IP, TCP/UDP) added later by the operating system (not by program A).
Once B has the frames, it can change them (assuming it knows where and how to do it - offset into the frame, recalculating checksums and so on), but then it has the problem of how to resend them from userspace so that they appear as they are on the wire. To do that you need the AF_PACKET raw socket (at least under Linux; I suppose equivalent functionality is available under other operating systems). See for example here (but google finds many results): http://austinmarton.wordpress.com/2011/09/14/sending-raw-ethernet-packets-from-a-specific-interface-in-c-on-linux/
Note that the way B changes the frames can influence the way they come back (notably the source MAC address should be set appropriately depending on the need).
http://austinmarton.wordpress.com/2012/06/03/receiving-raw-packets-in-linux-without-pcap/
http://austinmarton.wordpress.com/2011/09/14/sending-raw-ethernet-packets-from-a-specific-interface-in-c-on-linux/
ETH0 (192.168.1.0/24) <== DECODING FRAMES <===== ETH1 (172.168.2.0/24
I also would like to solve this and tried to think about a generic solution for Android.
It would help if you let me know your specific need for the tap, is that a VPN or anything else ?
Alex
Marc
If you run a program that opens /dev/net/tun and actually attaches to the tun interface, you perform the equivalent of plugging the cable into a physical ethernet interface; that provides the carrier to the interface and traffic can flow. I hope I'm understanding your issue correctly.
# cat /sys/class/net/tap0/operstate
down
# ip link set dev tap0 up
# cat /sys/class/net/tap0/operstate
down
No error is given, the operstate stays down, and as expected tcpdump doesn't see the packets.
# cat /sys/class/net/tap0/operstate
up
Marc
That said, I don't know of any workaround, short of creating a simple stub program (can even be much simpler than simpletun) whose only purpose in life is to keep the tun interface "connected" for the duration of the capture or whatever you are doing with it.
marc
Thanks for a great tutorial. I was trying to create two tap interfaces, attach it to a linux bridge, send frame via one tap interface and hoping to receive from the other tap interface. Your tutorial helped me code it up. Since, i send raw packets, i couldn't use read/write. I did a tcpdump on the sending tap interface and verified the sending side is ok. But, the receive side doesn't seem to receive anything. Here's my code snippet, appreciate if you or anyone can spot anything wrong. I have removed the error checks and constructed the frame manually. Both the tap interfaces are in UP/RUNNING state.
-------------
int sockfd;
.. }
ifr.ifr_flags = IFF_TAP ;
strncpy(ifr.ifr_name, "SEND_TAP", IFNAMSIZ);
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ){
... }
if( (err = ioctl(fd, TUNSETPERSIST, (void *) &ifr)) < 0 ){
.. }
memset(&ll, 0, sizeof(ll));
ll.sll_family = PF_PACKET;
ll.sll_ifindex = 22; /* ifindex of SEND_TAP using ip link */
ll.sll_protocol = htons(ETH_P_ALL);
if (bind(sockfd, (struct sockaddr *) &ll, sizeof(ll)) < 0) {
....
nread = sendto(sockfd, buffer, sizeof(buffer), 0, (struct sockaddr *) &ll, sizeof(ll));
-------------
int idx;
int sockfd;
.. }
ifr.ifr_flags = IFF_TAP ;
strncpy(ifr.ifr_name, "RCV_TAP", IFNAMSIZ);
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ){
... }
if( (err = ioctl(fd, TUNSETPERSIST, (void *) &ifr)) < 0 ){
.. }
memset(&ll, 0, sizeof(ll));
ll.sll_family = PF_PACKET;
ll.sll_ifindex = 26; /* ifindex of RCV_TAP using ip link */
ll.sll_protocol = htons(ETH_P_ALL);
if (bind(sockfd, (struct sockaddr *) &ll, sizeof(ll)) < 0) {
....
nread = recvfrom(sockfd, buffer, sizeof(buffer), 0,
(struct sockaddr *) &ll, &addrlen);
..
Also note that if you use sockets you're putting yourself at the other side of the processing that a tun/tap interface does, that is, you're not using anything of what tun/tap is for.
nread = write(fd, buffer,sizeof(buffer)); /* fd is the same as the code i gave above for creating tap */
nread = read(fd, buffer,sizeof(buffer)); /* Again fd is the same */
08:54:20.987776 IP0 bad-len 1
0x0000: ca28 b2cf 1cd4 ed1a 0806 0001 0800 0604
0x0010: 0001 0202 0202 0202 c0a8 0101 ffff ffff
0x0020: ffff c0a8 0102 0000 0000 0000 0000 0000
0x0030: 0000 0000 0000 0000
Socket programming is not a replacement for the processing that tun/tap allows you to do.
With tun/tap your code plays the part of the wire/intermediary, whereas with sockets you are the original producer/final consumer of the packets.
I actually started with regular read/write like your example. But, in write() i was constructing my own frame. That didn't work for above reasons.
As i said, the reason for RAW socket is i may want to send raw ethernet frame (say lldp).
I'd say there's nothing tun/tap specific in your problem (apart from the device creation code, which can however also be done externally), that is, you would likely experience the same problems if using two regular physical ethernet interfaces connected to a bridge (which, btw, is a good way to check whether your code really works).
Without knowing the details of the kernel bridge implementation, I would check, in random order:
target MAC address - to decide out which bridge port to send out a frame, the kernel checks the target MAC address and sees on which port it has learned it. Note that this is NOT the MAC address of the interface/port participating in the bridge. If you want the kernel to send a frame with a MAC of 00:11:22:aa:bb:cc out of a given bridge port, you need to tell the bridge (via ARP or other means) that 00:11:22:aa:bb:cc is located behind that port. The MAC addresses of the interfaces that are themselves bridge ports are not used for anything (AFAIK), except to derive the MAC address of the bridge. On the other hand, it's true that if the destination MAC is unknown, the bridge should send the frame out all its ports.
MTU - the payload of the ethernet frame you send should not exceed the bridge MTU otherwise it's silently dropped, this is probably obvious but it's worth mentioning.
Create a bridge on one m/c with multiple interfaces including a tap interface
So, bridge is probably acting ok. If frame is received on any physical interface connected to the bridge, it does the proper forwarding to other ports.
If my program writes to the tap, quoting from above
"To the kernel, it would look like the tun/tap interface is receiving data "from the wire".
But, M/C2 has a linux bridge whose port is eth3 as well as two tap interfaces one for rx and another for tx.
Sending frame looks like:
1111 1111 1111 a80c 0dc0 fa41 8100 0051
The code when it dumps the buffer after the read() on tap interface produces:
00008100 111111111111a80c0d
Even though tcpdump on tap shows the frame as is, when read call returns it puts an extra 4 B at the beginning. I am not sure, but my guess is 2B of 0 and 2B of ethertype. And, when I do a "write" of the buffer back to the same tap interface, it all goes out fine and it works beautifully.
unsigned char buffer[] = {0x11, 0x11, 0x11, 0x11, 0x11, 0x11, 0xa8, 0x0c, 0x0d, ….};
The code when it dumps the buffer after the read() on another tap (rx one) interface produces:
00000800 1111a80c0dc0f
It has truncated the 4B of DMAC and has put some 4B of data at the beginning. If i construct the frame with 4 leading Bytes like:
unsigned char buffer[] = {0x00, 0x00, 0x81, 0x00, 0x11, 0x11, 0x11, 0x11, 0x11, 0x11, 0xa8, 0x0c, 0x0d, ….};
It goes out fine and the packet looks correct.
I tried your simpletun example and I couldn't make it work. I must miss something that I'd appreciate your help:
- remote host has ip 'a', local host has ip 'b'
- TUN 'virtual1' was created on remote host, with ip '10.0.0.10'
- TUN 'virtual1' was created on local host, with ip '10.0.0.20'
- started simpletun on local host with: simpletun -i virtual1 -c b (where b is the real ip address of the remote host)
Thank you!
mike-
If the last command fails with "connection refused" or some other error, you have a basic connectivity problem between "a" and "b".
If it says nothing, chances are it has correctly connected and you can start exchanging traffic between a's tun/tap IP and b's tun/tap IP.
You can also add the -v option to both client and server command line, that should give you some more info.
I've tried openvpn for this scenario but it didn't work.
APP1 -> OPENVPN -> SERVER1 -> NETWORK -> SERVER2 -> OPENVPN -> INTERNET
What I want to do basically is have server2 mask the source of app1. Problem is that app1 uses a lot of connections, like 10k and openvpn can't handle that much and is very slow. We tried UDP, TCP and various MTUs but we can't do it. I was wondering if ip tuntap was a good option.
As for the rest of your question, sorry but the lack of useful information is such that I'm not able to make any sense out of it.
Right now I'm using GRE or IPIP tunnels.
I have an application running on server 1, let's say a tool that run DNS queries.
This application binds to the IP 10.0.0.1. This traffic is PBRd to 10.0.0.2 on server 2.
On server 2 I forward all the traffic from 10.0.0.0/24 to the internet.
So if on server X (outside my network) a connection on the port 53 is received from server1, on their logs it will show up with the IP of server 2.
Now what I want to do, is use TUN/TAP instead of IPIP or GRE beacuse I'm working iwth openvz containers and they don't allow GRE or IPIP. With openvpn the performance was very very bad and I want to develop or use something that can suit the number of connections I require.
Does it make sense?
- Whatever you did with those tunnels, can be done with two tun/tap interfaces, one at each end of the tunnel
- While with GRE and IPIP it's the kernel that does all the work, with tun/tap things happen in userspace and it's your code that has to implement the tunnel
- It is possible to run multiple instances of OpenVPN on the same machine
- If you end up implementing the same I/O model as OpenVPN, you'll likely experience the same problems you had with it (perhaps a bit mitigated by the fact that you don't do encryption), so you have to implement something better.
2) If the external computer pings 192.168.0.1 from eth1, given the fact that the interface is not up, will this packet reach the tun interface? What happens if there is a rule to drop all from eth1, will it reach the tun (after all the real interface is down)?
If a packet enters eth0 and iptables drops all packets entering eth0, they will be dropped and thus will not reach eth5, or tun0, or whatever other interface.
If a packet enters eth1 and it is down, it is dropped even before iptables has a word on it.
In short, iptables-wise there's no difference between a tun interface and another physical interface.
I suggest you read up some basic networking concepts. For iptables, a good reference (though a bit outdated) is https://www.frozentux.net/iptables-tutorial/iptables-tutorial.html.
http://stackoverflow.com/questions/21001713/usage-of-tun-tap-and-multicast-messages
However without the code of the application it's not possible to reproduce the setup and try to investigate the problem.
Dmitry
ip link set dev tap2 up
ip addr add 10.0.0.1 dev tap1
ip addr add 20.0.0.1 dev tap2
Probably, if you set tap2 in promiscuous mode (via iproute2 or from your code) the frame would be accepted and your application would see it. But as usual, it all depends on what you're trying to achieve.
You'll have to add that IFF_NO_PI must be used, if any, ONLY for tun interfaces.
For tap interfaces, it will add four extra leading bytes that are unuseful but to add garbage to an Ethernet frame (and shift the whole frame with 4 bytes).
The difference is that the latter architecture describes a connection between lxc containers and the host machine. And what i am trying to do is almost the same thing but using real machines instead of lxc containers.
The tap and bridge configuration is described in the file : https://github.com/nabam/ns3/blob/master/examples/tap/virtual-network-setup.sh (without the lxc configuration)
The architecture is better described on this page ("Big picture" section) : http://www.nsnam.org/wiki/index.php/HOWTO_Use_Linux_Containers_to_set_up_virtual_networks
How can I connect eth0 of MachineLeft to NS3's Eth0 virtually ?
2) Why can't we set IP address for it in the same subnet as in for the real physical interface conected
with an internet ? I found that setting it in the same subnet causes to stop internet access.
3) (Here) When ping is used with 10.0.0.2 (or any address within 10.0.0.2 - 10.0.0.254) why it gets travelled to tap ineterface ?
2) If you assign IP addresses that are in the same range to different interfaces you can be in trouble unless you properly configure routing, This is an advanced topic and I would not recommend it unless you have very specific needs that require that, and know what you're doing.
3) Because the kernel sees that the address is not local, and the route to reach it points to the tap interface. This is exactly the same that happens with any interface, be it virtual or physical..
does TAP interface works with DHCP. DHCP client is running in the application program waitng for data at port 67. but, TAP does not pass DHCP offer to DHCP client.
I have created two Threads (with pthread) and both call 'read()' but only one Thread (always the same) comes back with Data and the other Thread is blocked for ever.
Is the second Thread only used in Situations with higher Load?
Exist similar Problems at writing to an TAP-Device?
Erik
In my opinion is read a threadsafe Function/Syscall and the Linux-Kernel must do that not multiple Callers read the same Data.
But if the TAP-Device is a "normal" File-Descriptor than should it have the same Rules as all other File-Descriptors to, i try to find a Linux specific Documentation for this Topic.
Erik
Without checking, I would think that read() is thread-safe, however you can't go wrong if you implement synchronization and locking yourself, rather than relying upon the underlying implementation.
I have used source /tap driver provided by openvpn, I start with a simple program which reads frame over tap descriptor.
"netsh interface ip set address my_tap_iface static 10.0.0.1 255.255.255.0"
Can anyone suggest proper configuration steps as described above in the tutorial for linux, and also what are the recommended settings for firewall.
"iptables -t nat -A POSTROUTING -s 10.0.0.0/24 -o eth0 -j MASQUERADE".
First of all, I'm going to thank you for this nice tutorial.
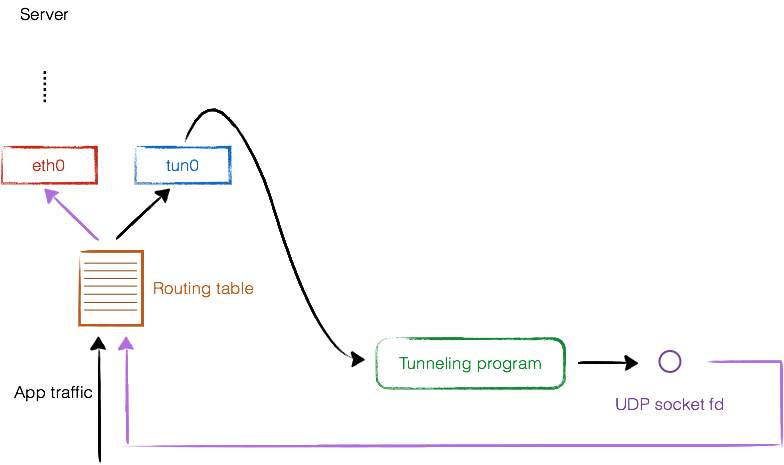
Second of all, I'm gonna implement a udp tunnel based on this tutorial. in the first version, while there is only on client, it works fine. but in a situation that multiple clients want to connect to the server, it can get all from socket and write it to the tun file descriptor, but when comes to get the data from tun_fd, it should make its own choice to send it back to which of the remote clients. the easies way comes to mind, is to create multiple tun_fd for each connection from clients and make a thread for waiting for that tun_fd and each tun_fd is for exactly one client connection.
you mentioned that it is possible to make a tun/tap presistance and with the same owner, connecting to it with every proccess,
I created a tun and setted it presistant. then closed the program and connected to the tun again. So it worked. but all I need is to able to connect multiple times to the same tun from the same program to have multiple tun_fd for each connection. but whenever I call the tun_alloc from my program, it gives me this crap: "ioctl(TUNSETIFF): Device or resource busy"
I tried the forking and pthreading yet still the result is the same.
it is said that the 3.8 kernel has added the multiple queuing capabilites but I have not upgrade to it yet, and am still wondering how openvpn is doing that (have not taken a looked at its sources).
so any thoughts?
thanks
Something that i missed in this tutorial and that i wanted to know is ..
I set up a TUN interface using C program and its UP as well...I wanted this interface to be assigned IP(v6) through the SLAAC procedures since thats the behaviour i observed for my eth0 interface.(when eth0 is brought up it sends out router-solicitaions and the procedure for IPv6 acquision completes). Don't TUN/TAP interfaces behave the same way as normal interfaces and can acquire the IP normal procedures? OR the creater takes care of IP allocation on behalf of these TUN/TAP interfaces?
{
printf("open failed\n");
return INVALID_HANDLE;
}
* IFF_TAP - TAP device
*
* IFF_NO_PI - Do not provide packet information
*/
ifr.ifr_flags = IFF_TUN | IFF_NO_PI;
sprintf(ifr.ifr_name, "%s%d", TAP_IF_NAME_PREFIX, dev_num++);
printf("ioctl failed: %d\n", errno);
close(fd);
return INVALID_HANDLE;
}
{
perror("TUNSETPERSIST");
return INVALID_HANDLE;
}
if ((sockfd = socket(AF_INET6, SOCK_DGRAM, 0)) ifname);
inaddr->sin_family = AF_INET6;
inaddr->sin_port = 0;
if(ioctl(sockfd, SIOCSIFFLAGS, (void *) &ifr) ifname);
perror("");
return 1;
}
perror("");
return 1;
}
memcpy(ipv6_linklocal_addr, netArgs->ipv6_configuration.hostIPv6, NUMBER_OF_IPV6_OCTETS);
ipv6_linklocal_addr[0] = 0xFE;
ipv6_linklocal_addr[1] = 0x80;
memcpy(&ifr6.ifr6_addr, ipv6_linklocal_addr, NUMBER_OF_IPV6_OCTETS);
ifr6.ifr6_ifindex = ifr.ifr_ifindex;
ifr6.ifr6_prefixlen = 0;
perror("");
return 1;
}
tried it on debian wheezy and it worked...it has kernel 3.2 i guess..
This needs further investigation.
maybe this is a clue?
I thought someone here might help with my issue.
Does my P-t-P address need to be different from the local TUN address (it's the same in simpletun)? If so, in what range?
Any idea what needs to be done to fix this?
Ip addresses used:
master: tun0 = 10.0.0.1, eth0 = 192.168.0.101
slave: tun0 = 10.0.0.2, eth0 = 192.168.0.102
--------------------------
# wireshark output - sending and receiving ping requests works, but there's no ping response by either side.
tshark: Lua: Error during loading:
[string "/usr/share/wireshark/init.lua"]:45: dofile has been disabled
Running as user "root" and group "root". This could be dangerous.
Capturing on tun0
0.000000 10.0.0.2 -> 10.0.0.1 ICMP 84 Echo (ping) request id=0x0145, seq=1/256, ttl=64
1.001133 10.0.0.2 -> 10.0.0.1 ICMP 84 Echo (ping) request id=0x0145, seq=2/512, ttl=64
7.965560 10.0.0.1 -> 10.0.0.2 ICMP 84 Echo (ping) request id=0x2505, seq=1/256, ttl=64
9.764407 10.0.0.1 -> 10.0.0.2 ICMP 84 Echo (ping) request id=0x2506, seq=1/256, ttl=64
------------------------
# ifconfig output - Number of RX packets == dropped on both sides (unless 10.0.0.3 would be pinged).
# ARP is still on when using tun_open(), but according to the Linux Device Drivers book that flag is ignored for point-to-point connections
# ifconfig output for the slave - simpletun works with these same settings (I tried to turn ARP on manually for Simpletun, and it still worked fine)...
tun0 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:10.0.0.2 P-t-P:10.0.0.2 Mask:255.255.255.0
UP POINTOPOINT RUNNING MULTICAST MTU:1500 Metric:1
RX packets:2 errors:0 dropped:2 overruns:0 frame:0 # after 2 ping requests from 10.0.0.1
TX packets:2 errors:0 dropped:0 overruns:0 carrier:0 # after 2 ping requests to 10.0.0.1
collisions:0 txqueuelen:500
RX bytes:252 (252.0 B) TX bytes:168 (168.0 B)
I set the server IP= "10.0.0.1/24" and p-t-p="10.0.0.1/24".
For the client, it's "10.0.0.2/24" and p-t-p="10.0.0.2/24".
Libdnet/libdumbnet has a special intf_entry struct to set up the interface (my main reason for using it), but I'm probably not using it right.
It sets only these variables before calling intf_set(), which is the equivalent of "sudo ip ..."
strlcpy(ifent.intf_name, tun->ifr.ifr_name, sizeof(ifent.intf_name)); /* the name ("tun%d") */
ifent.intf_flags = INTF_FLAG_UP|INTF_FLAG_POINTOPOINT; /* P-t-p interface and starts UP */
ifent.intf_addr = *src; /* interface address+bitmask - converted from string */
ifent.intf_dst_addr = *dst; /* point-to-point dst+bitmask - converted from string */
ifent.intf_mtu = mtu; /* interface MTU - set to 1500 */
Only IFF_TUN is set for the tun connection.
--------------
@@ -45,7 +45,7 @@
- tun->ifr.ifr_flags = IFF_TUN;
+ tun->ifr.ifr_flags = IFF_TUN | IFF_NO_PI;
- return (writev(tun->fd, iov, 2));
+ return (write(tun->fd, buf, size)); // 4 bytes longer than the result of (writev(...))
+ return (read(tun->fd, buf, size)); // same length as the result of (readv(...)-sizeof(type))
--------------
Sending this 4 byte packet info seems to mess something up and cause packets to be dropped...
I guess I just need to contact the packet maintainer instead of ranting in the comment section of 3 year old blog posts.
However, if I change the source IP and replace it with IP of some remote m/c it works fine.
sysctl -w net.ipv4.conf.eth0.rp_filter=0
sysctl -w net.ipv4.conf.tun0.rp_filter=0
echo 1 > /proc/sys/net/ipv4/ip_forward
Also to you should also set net.ipv4.conf.all.rp_filter to 0, since "The max value from conf/{all,interface}/rp_filter is used when doing source validation on the {interface}", so if you have nonzero in "all" it will override the interface value. Without knowing exactly what you're doing it's difficult to say more.
/dev/net/tun0 was a typo.I would like to aplogize for that. What I have used is actually /dev/net/tun.
>them back again, if you change even a single bit you have to recalculate all the > relevant checksums. Are you sure you're doing it correctly?
src IP - 172.26.192.150 ( local machine)
dest IP - 172.26.192.128 ( remote machine)
In the case the packet gets lost after written to TUN
If I change the src IP of the intercepted packet,recalculate the required checksum and re-inject that packet, the packet gets forwarded to the proper interface.
src IP - Changed from 172.26.192.150 ( local machine) to 172.26.192.149 ( remote machine)
dest IP - 172.26.192.128 ( remote machine)
This condition works.
Kernel details : 3.1.0-7.fc16.i686.PAE
Assigned an IP to the TAP interface using,
that it assigns an IP address 10.0.0.1 to the tap0 interface and
it also specifies subnet mask for tap0 is 255.255.255.0,
IP address ranges from 10.0.0.0 to 10.0.0.254 (except 10.0.0.1)should be destined(or forwarded)
to the tap0 interface where user application attahched to tap0 can read those frames."
"Though it explained as Linux kernel has ping server which respond to that" Can u clarify this more.
write it over the tap0, and I wanted to capture ping ICMP reply of the same over
the TAP interface over `wireshark`, One application is attached with TAP to read and write ethernet frames.
like pinging IP address of LAN network, and having ping reply.
created by User application attached to TAP interface, through the Host Ethernet
port(eth0) which is connected to the internet,
And the received ping icmp response over eth0 should be forwarded to TAP
interface IP address(i.e. consider 10.0.0.1)
If you remove this special local route, the kernel will no longer know that the destination is local, and will indeed send packets out the interface, even those destined for the local IP address.
However note that removing the special local route pointing to the interface's IP address has other adverse consequences (for example the kernel will start sending out ARP requests for the IP address even if it's on a local interface), so you should do it only for testing purposes and then restore it.
Note that even when the local route is present (ie, the normal situation), you will be able to see traffic for local addresses on the loopback interface (lo), so if you ping the tap interface IP address and run tcpdump on lo, you will see the packets.
Note that it's entirely your code's responsibility to create and correctly fill each and every header, field and checksum at the ethernet, IP and ICMP layers. It's a lot of work, and it's very easy to do something wrong. Still, it can be a very useful experience. I'm going to assume that the frame you create is valid, with correct headers and checksums, otherwise the kernel will drop it. If you don't see anything entering the tap interface, that's probably the case.
a) changed the OPER field for ARP Reply(0x0002)
b) Alter(swap) SRC & DST IP address
c) Updated DST MAC with the received SRC MAC (i.e MAC addr of TAP)
d) Updated SRC MAC with(A1:B1:C1:D1:E1:F1)
How can I make it better to support other internet protocols in optimised approach.
Kindly share some optimum way to make it better.
What your code should do depends entirely on your goals; broadly speaking, you use the frame transmission/reception facilities provided by the "physical" adapter (eth0, tap, whatever) to build "something" on top of that. There's no rule that defines what this "something" should be; it could be a simple ping simulator as you did, or it can be a traffic analyzer, or an entire TCP/IP stack, or a VPN ... these are just examples, the possibilities are many; you decide. The tap interface is a tool that you use to implement whatever you want or need. So, sorry but I'm not going to suggest or recommend anything.
I believe that the Internet provides enough documentation and resources to undertake whatever project you want to pursue, if you are willing to learn and experiment.
I want to forward whatever ethernet frames comes to eth0 to tap0 and eth1 to tap1.
I used gnuradio which will receive tap0 and tap1 ethernet frames and modulate and send to remote system via usrp.
br0 have tap0 and eth0 interfaces attached, br1 have tap1 and eth1 interfaces attached.
I want to send data from my host to remote host via tap.
routing already done.
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether e8:11:32:01:4a:1e brd ff:ff:ff:ff:ff:ff
3: wlan0: mtu 1500 qdisc mq state UP qlen 1000
link/ether 4c:ed:de:74:b4:01 brd ff:ff:ff:ff:ff:ff
inet 10.154.148.117/22 brd 10.154.151.255 scope global wlan0
inet6 fe80::4eed:deff:fe74:b401/64 scope link
valid_lft forever preferred_lft forever
10: tap2: mtu 1500 qdisc pfifo_fast state UP qlen 500
link/ether 7e:5b:ea:9b:50:37 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.201/8 brd 10.255.255.255 scope global tap2
inet6 fe80::7c5b:eaff:fe9b:5037/64 scope link
valid_lft forever preferred_lft forever
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.154.148.0 0.0.0.0 255.255.252.0 U 2 0 0 wlan0
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 wlan0
10.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 tap2
0.0.0.0 10.154.148.1 0.0.0.0 UG 0 0 0 wlan0
Address HWtype HWaddress Flags Mask Iface
10.0.0.101 (incomplete) tap2
10.154.148.1 ether 00:15:c7:62:3c:00 C wlan0
bishneet@bishneet:~$ sudo ip addr show
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:25:64:9c:d2:0c brd ff:ff:ff:ff:ff:ff
inet 128.243.35.15/24 brd 128.243.35.255 scope global eth0
inet6 fe80::225:64ff:fe9c:d20c/64 scope link
valid_lft forever preferred_lft forever
6: tap2: mtu 1500 qdisc pfifo_fast state UP qlen 500
link/ether de:ae:06:db:5b:35 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.101/8 brd 10.255.255.255 scope global tap2
inet6 fe80::dcae:6ff:fedb:5b35/64 scope link
valid_lft forever preferred_lft forever
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
128.243.35.0 0.0.0.0 255.255.255.0 U 1 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 eth0
10.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 tap2
0.0.0.0 128.243.35.1 0.0.0.0 UG 0 0 0 eth0
Address HWtype HWaddress Flags Mask Iface
128.243.35.1 ether 00:15:c7:24:4a:c0 C eth0
10.0.0.201 (incomplete) tap2
10.154.148.117 (incomplete) tap2
Thanks
I am running a Ubuntu 12.04 Virtual Machine. I am doing exactly this:
root@sarumm-Ubuntu:/dev/net# openvpn --mktun --dev tun3
Thu Apr 4 16:22:04 2013 TUN/TAP device tun3 opened
Thu Apr 4 16:22:04 2013 Persist state set to: ON
root@sarumm-Ubuntu:/dev/net# ip link set tun3 up
root@sarumm-Ubuntu:/dev/net# ip addr add 10.0.0.1/24 dev tun3
sarumm@sarumm-Ubuntu:~$ ping 10.0.0.1
inet addr:10.0.0.1 P-t-P:10.0.0.1 Mask:255.255.255.0
UP POINTOPOINT NOARP MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
tshark: Lua: Error during loading:
[string "/usr/share/wireshark/init.lua"]:45: dofile has been disabled
Running as user "root" and group "root". This could be dangerous.
Capturing on tun3
Thanks in advance.
- Applications will send UDP data to this IP address.
- A userland application will attach to the tap and do some processing of the packets and then forward them on to a non network custom hw device.
[sudo] password for beaty:
Set 'tun9' persistent and owned by uid 1000
ioctl(TUNSETIFF): Invalid argument
Error connecting to tun/tap interface tun9!
crw-rw-rwT 1 root root 10, 200 Dec 2 11:31 /dev/net/tun
Linux emess 3.2.0-34-generic-pae #53-Ubuntu SMP Thu Nov 15 11:11:12 UTC 2012 i686 i686 i386 GNU/Linux
I have scenario here, where in I am developing L2 control plane for distributed data plane for a switch,
The control plane would be running Linux on control cards and remaining all the cards have fast path L2 data plane. All data planes will have 4 to 6 ports and each port will be part of bridge.
L2 Control plane protocols are executed on Control cards, BPDUS are received by Data Plane at first and sent back to Control plane card via tcp. Question is whether I can create tap device(bridge) in control plane card and do the bridge state changes in control plane card and will the state change effect the port states in L2 data plane card
Regards
Raghu
Thanks for your answer!
I still think there is an error in the text; it says:
If you configure tun77 as having IP address 10.0.0.1/24 and then run the above program while trying to ping 10.0.0.2 (or any address in 10.0.0.0/24 other than 10.0.0.1, for that matter), you'll read data from the device:
Fri Mar 26 10:48:12 2010 TUN/TAP device tun77 opened
Fri Mar 26 10:48:12 2010 Persist state set to: ON
# ip link set tun77 up
# ip addr add 10.0.0.1/24 dev tun77
# ping 10.0.0.1
...
$ ./tunclient
Read 84 bytes from device tun77
Read 84 bytes from device tun77
...
other console we will not see traffic.
Rami Rosen
http://ramirose.wix.com/ramirosen
is some trivial error which won't let it work; I tried it. it says:
then run the above program while trying to ping 10.0.0.2
(or any address in 10.0.0.0/24 other than 10.0.0.1, for that matter),
you'll read data from the device:
Fri Mar 26 10:48:12 2010 TUN/TAP device tun77 opened
Fri Mar 26 10:48:12 2010 Persist state set to: ON
# ip link set tun77 up
# ip addr add 10.0.0.1/24 dev tun77
# ping 10.0.0.1
In the example above, it should have been ping to 10.0.0.2
(or any other address in this subnet, other than 10.0.0.1)
>Perhaps the code should check whether the interface exists >before doing anything.
It is not simple as that. Suppose that the tun kernel code (drivers/net/tun.c) will check and see that the interface does **not** exist. So what ? should it return an error ? I think that it should **not** return an error. The reason is simple: when you add a device you *also* use TUNSETIFF ioctl, not only in deleting a device.
And when you add a new device, you don't expect it to exist.
for adding and one for deletion.
ip tuntap add tun0 mode tun
ioctl(TUNSETIFF): Device or resource busy
http://ramirose.wix.com/ramirosen
ioctl to the tuntap driver for delete and checks the return value. It indeed does not check existence before.
an error if the interface does not exist. But with
tuntap driver, this is not the case. The driver implementation is a unique one in the tuntap driver,
as in add/delete we use a pair of identical ioctls,
TUNSETIFF and TUNSETPERSIST(the second with different values according to the action, add/delete).
Rami Rosen
http://ramirose.wix.com/ramirosen
I think there is something which is a bit wrong with the linux tun driver.
I use the recent iproute2 from git.
If I run:
ip tuntap add tun2 mode tun
and by error try to delete a non existant tun interface like:
ip tuntap del tun3 mode tun
I don't get an error.
The same is with tap.
first you have an ioctl of TUNSETIFF.
This same ioctl is used in delete.
So you register a new net device.
Then there is a second ioctl. In case of delete, it is the non persistent ioctl (TUNSETPERSIST).
This ioctl unregisters the tun/tap device.
So no error is returned.
Rami Rosen
ifconfig tun0 hw ether 02:00:27:E1:1E:ff
SIOCSIFHWADDR: Operation not supported
What you want to do works if the device is a tap (layer 2) interface:
kernel: TRACE: mangle:PREROUTING:policy:1 IN=tun0 OUT= MAC= SRC=x.x.x.x DST=192.168.10.1 LEN=276 TOS=0x00 PREC=0x00 TTL=60 ID=50435 PROTO=UDP SPT=53 DPT=60683 LEN=256
Glad you finally solved it!
On the other hand, the packet that the kernel sends to the tun device are OUTGOING packets, and as such they will be accounted and processed (and a program connected to the tun fd will be able to read() them).
The kernel determines whether the packet is valid, and whether it has to be delivered locally or routed. If it looks like it has to be delivered locally but there's no process to deliver it to, then it's dropped (depending on the actual type of packet, an error may be generated).
So to make it simple, if your kernel receives a packet from the tun interface (or any interface, for that matter) whose destination IP address matches the IP address of the tun interface, contains a TCP segment with destination port 80, but there's no process "owning" TCP port 80 in the system, then yes, the packet is dropped, and depending on the type of packet, the kernel may send back a TCP RST, or an ICMP error message. Note that (depending on the routing setup) it's quite likely that this error message will go out the same tun interface from which it came in, and your program that is connected to the tun file descriptor should be prepared to catch those packets.
In any case, no device is created under /dev (apart from the already mentioned /dev/net/tun).
tun77 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:10.1.1.1 P-t-P:10.1.1.1 Mask:255.255.255.0
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 155.53.129.254 0.0.0.0 UG 0 0 0 eth0
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 tun77
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
155.53.128.0 0.0.0.0 255.255.254.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
at the end of this article, it says, "Finally, it's worth noting that if the tunnel connection is over TCP,
we can have a situation where we're running the so-called "tcp over tcp"; ",
which implies that the tunnel described above isn't an over-TCP tunnel, right?
(i.e. if we have created "if1" interface and now try to create
"if1:1" using the same procedure) will the fds returned by ioctl
be same for these two interfaces?
that clones and replaces it with a tap device i want to run it as a multi threaded daemon
with a management socket to control it.
network and segregate it based on mac address also enable disable traffic based on time
throughput constraints as with internet cafes chillispot / coova is another good example of
tun used in a captive portal.
traffic will be written to this tap directly without 802.1Q.
The flags are always 0x0000 and the protocol is the same as in the Ethernetframe (offset 12).
In case of a TAP-Device, the MTU means the payload of the ethernet frame and the ethernet header (with or without VLAN-Tag) are additional data, correct?
That means my buffer must be at least MTU + 14/18 (without/with VLAN-Tag), correct?
Erik
ip link set dev tap20 mtu 1600ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
and it works perfectly for my needs.
The same problem is with setting the TAP-Device up, at the moment i do this manually in an additional console with "ifconfig tap0 up" but this is not practicable for the final program.
Do you have any idea?
Goggle has no help for me.
Thanks a lot for your help
There is a trick: one must open a normal socket (UDP in this case) and use the ioctl syscall with this socket-file-descriptor and not with the file-descriptor of the TAP-Device but with the ifreq-variable of the TAP-Device. After finish the configuration of the TAP-Device the socket can closed. This trick should be a little bit more highlighted in the description, in my first reading of the source code i do not have seen it.
Thousand and One Thanks for Your Help.
Erik
As you suggested it is good just for specific case, I want to be able to select traffic for instance even based on the packet length. That s why I need iptables (mangle / nat), because I have more options in order to split the traffic in more interfaces.
tcpdump -i tun2
(..)
tcpdump -i tunN
having known that the traffic is coming from and going to the real interface eth0, I want to send a copy of it (selected by filter of iptables) to tun1, tun2, .. tunN.
Thanks a lot for your help
To be honest, if your traffic is coming from a SPAN port or equivalent (ie, not destined to the machine where tcpdump is running), I think iptables wouldn't even see it.
I think, if I understand you correctly, that you need policy routing rules to route traffic differently based on protocol. In your specific example of tap1 and tap2, you could create a second routing table where traffic is routed out tap2, then mark ICMP traffic with iptables, and finally add a routing rule which uses the alternate routing table for marked packets. You can find some theory at http://linux-ip.net/html/routing-tables.html and some examples at http://linux-ip.net/html/adv-multi-internet.html and generally googling for "linux policy routing" should turn up something.
and when I wanna do that, for sure I need to give them an interface, isnt ?
Ok, when you check some info into the traffic it s better to reduce it somehow just selecting the one you more need to check. In this way the process is less stressed overall when it receives high rate traffic.
Because of that I would like to route traffic incoming from eth0 into two virtual interfaces, the place where I attach a monitoring software, as tshark, tcpdump, etc.
What do you think?
If you want to capture only a certain type of traffic, you can specify filters to tcpdump, for example
tcpdump -i eth0 icmpwill capture only ICMP traffic, ortcpdump -i eth0 tcp port 80will capture (hopefully) only HTTP traffic, etc. The manual page for tcpdump, or pcap-filter, provides all the details on the syntax to use for filtering.Hope this answers your question.
" - /dev/tunX - character device;
- tunX - virtual Point-to-Point interface.
and kernel will receive this frame from tunX interface.
In the same time every frame that kernel writes to tunX
interface can be read by userland application from /dev/tunX
device."
Anyway, to write data to the kernel (although it's not much clear what you mean with that; you're probably trying to do something else, which you don't explain): briefly, as explained in the tutorial, you have to open /dev/net/tun to get a file descriptor which can then be used to send/receive packets to/from the kernel. It's all explained in the article, including sample C code.
Here is an example, which uses IPv6 multicasts:
Juergen
the above was meant as a reply to the post of DoDo.
PING 192.168.2.22 (192.168.2.22): 56 data bytes
^C
--- 192.168.2.22 ping statistics ---
13 packets transmitted, 0 packets received, 100% packet loss
Waiting for data in
inet addr:192.168.2.2 Bcast:192.168.2.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:1 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Chain INPUT (policy ACCEPT)
target prot opt source destination
target prot opt source destination
target prot opt source destination
tun0 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:192.168.2.2 P-t-P:192.168.2.2 Mask:255.255.255.0
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
ioctl(TUNSETIFF): Invalid argument
Error connecting to tun/tap interface tun0!
(This worked with 2.6.32-34 - I saw traffic via tshark)
Thu Oct 20 22:02:50 2011 TUN/TAP device tun3 opened
Thu Oct 20 22:02:50 2011 Persist state set to: ON
host$ sudo ip link set tun3 up
host$ sudo ip addr add 10.0.0.1/24 dev tun3
host$ ifconfig tun3
tun3 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:10.0.0.1 P-t-P:10.0.0.1 Mask:255.255.255.0
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
From 10.0.0.1 icmp_seq=1 Destination Host Unreachable
From 10.0.0.1 icmp_seq=2 Destination Host Unreachable
From 10.0.0.1 icmp_seq=3 Destination Host Unreachable
--- 10.0.0.2 ping statistics ---
5 packets transmitted, 0 received, +3 errors, 100%packet loss, time 4018ms
When running the above (which basically matches the example you provided)
the behaviour is different depending on kernel versions.
When you start pinging 10.0.0.2 you will see packets on tshark -i tun3
when pinging 10.0.0.2 *nothing* appears on tshark -i tun3
Is that what should happen.
If no process is attached, the test you are running (and which I too run in the article) now fails because the interface is down and packets are dropped and not "transmitted". I've put a note in the article to point out that what is described there works only with kernels < 2.6.36.
I understand the patch does the right thing, as having a process attached to the tun fd is the equivalent of having the "link up" for a tun interface; however, for the purposes of the article, this is a bit of a loss because the simple test described there to show how the interface works cannot be done anymore.
Thanks!
But I don't get it working.
I also changed the sock fd to UDP style:
code:
-----------------------------------------------
if ( (sock_fd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
perror("socket()");
exit(1);
}
-----------------------------------------------
When i compile and start the client and server i see the creation of a UDP socket of 55555 with an established note by netstat.
Howeven when i send data from the client to the server i see the debug with the amount of bytes to the tap interface and the amount of bytes to the network, this data is not coming to the server.
When i initiate a ping from the server to the client (not is debug mode) i see text popping up on the screen, this text is the
datafield of a ICMP packet that i try to send to the client side of the tunnel.
I'm doing something stupid but i just can't figure it out...........
brctl addbr test
ip tuntap add mode tap tap0
ip tuntap add mode tap tap1
ifconfig test up
ifconfig tap0 up
ifconfig tap1 up
brctl addif test tap0
brctl addif test tap1
etherwake -b -i tap0 00:00:00:00:00:00
arping 192.168.1.2
root@computer:~# ifconfig test
test Link encap:Ethernet HWaddr 02:07:b1:eb:2c:2a
inet6 addr: fe80::944b:d9ff:fe10:b240/64 Scope:Link
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:19 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:3377 (3.2 KiB)
tap0 Link encap:Ethernet HWaddr 02:07:b1:eb:2c:2a
inet addr:192.168.10.0 Bcast:192.168.10.255 Mask:255.255.255.0
inet6 addr: fe80::7:b1ff:feeb:2c2a/64 Scope:Link
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:278 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
root@computer:~# ifconfig tap1tap1 Link encap:Ethernet HWaddr b2:ee:2c:f9:d5:0d
inet6 addr: fe80::b0ee:2cff:fef9:d50d/64 Scope:Link
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:19 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
root@computer:~# brctl show
bridge name bridge id STP enabled interfaces
pan0 8000.000000000000 no
test 8000.0207b1eb2c2a no tap0
tap1
root@computer:~# brctl showmacs test
port no mac addr is local? ageing timer
1 02:07:b1:eb:2c:2a yes 0.00
2 b2:ee:2c:f9:d5:0d yes 0.00
root@computer:/home/iszczesniak# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.2.0 0.0.0.0 255.255.255.0 U 2 0 0 eth1
192.168.10.0 0.0.0.0 255.255.255.0 U 0 0 0 tap0
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 eth1
0.0.0.0 192.168.2.1 0.0.0.0 UG 0 0 0 eth1
Irek
| ^
v |
tap0 |
intf |
| |
v |
application
inet addr:192.168.13.5 P-t-P:192.168.13.5 Mask:255.255.0.0
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:6500 Metric:1
RX packets:8617887 errors:0 dropped:0 overruns:0 frame:0
TX packets:6127019 errors:0 dropped:20 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:551235232 (525.6 MiB) TX bytes:391798708 (373.6 MiB)
Steve
ifconfig tun1 192.168.13.5/16 txqueuelen 50
inet addr:192.168.13.5 P-t-P:192.168.13.13 Mask:255.255.0.0
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:64996 errors:0 dropped:0 overruns:0 frame:0
TX packets:370163 errors:0 dropped:59 overruns:0 carrier:0
collisions:0 txqueuelen:50
RX bytes:2169920 (2.0 MiB) TX bytes:39235816 (37.4 MiB)
Steve
Ok, so how do you generate the traffic? For packets to be sent "out" the tun1 interface, they should have a destination IP address in the range 192.168.0.0/16 (except, of course, 192.168.13.5 itself). Alternatively, the host should have a route to whatever destination address is in the packet, and that route should point to the tun1 interface.
That way, if you attach an application to the descriptor corresponding to tun1, that application should receive the packets that the kernel routes out tun1.
So, how does your application connect to the tun1 interface descriptor, and how do you actually read the packets? Also, how does the application-level program generate the UDP datagrams?
My Userland API which sends out packets uses 32bit Int values so I adjusted the Tap Read to read 32bit integers.. For some reason when I do a read I am always 8 bytes short in the value returned for the number of bytes read. TCP Dump on another machine shows this so I never get replys to my ICMP ping.. If I add 8 bytes to number of bytes read, the ping packet is valid so the data is there & it all works properly. However.. this is a hack & want to understand what's going on here.
I am assuming this is an issue with the Linux Read System call & 32bit integers.. have you seen this before? I could keep the rx buffer as char buffer but casting gets messy in C++ since the API takes a structure & a 32bit int pointer to data.
_this->_buffer,
sizeof(buffer);
_this->_buffer,
sizeof(buffer);
IP truncated-ip - 456 bytes missing! 192.168.0.77 > 192.168.0.76: ICMP echo request, id 2796, seq 557, length 520
Also you're using _this->_buffer but the name of the array is just "buffer" with no underscore. Is that meant to be the same variable?
int32_t length
..etc..etc..
so in C++ it saves trying to reinterpret cast a 32bit pointer onto an 8 bit Array although I can do that & it does work.. if the buffer is int32_t I can just say
buffer->data = &_test_buffer[0];
and be done with it
data = (int32_t *)malloc(_MAX_MTU_SIZE);
This is a great tutorial given the rather sketchy txt file that comes with the Tap Tun interface and has helped me get a tap interface up and running. I am trying to forward Ethernet frames to an external API which cannot see the linux protocol stack. I am nearly there but wondered if I am missing something. When I read in ethernet frames they do not seem to conform to spec. I see no pre-amble. I am assuming the interface is filtering that out but yet the source and dest mac addresses seem to be in the wrong place. As "read" is a blocking call, when a packet arrives at my tap interface which is set-up as instructed, I wait for the bytes read... for example a simple ICMP ping. I see the correct number of bytes.. I dump the packet buffer to a txt file and expect to at least see a length field at the specified place.. I can see the TCP header starting with the version but it seems to be in the wrong place. Am I missing something. Is there something I am seriously overlooking here? any help would be really appreciated as I am loosing sleep over this.
Also if the frames you're reading are coming from the external application, make sure that they are correctly formed, that they are of type ethernet II/DIX, and also watch out for added fields like VLAN tags etc. Ah and of course if you can sniff the traffic with Wireshark or tcpdump, that will also be a great help. Finally, make sure that fields longer than one byte are using the correct endianness.
struct ifreq ifr;
int tuntap_fd, err;
char *tundev = "/dev/net/tun";
perror("opening /dev/net/tun");
return tuntap_fd;
}
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
}
else { //TUN
ifr.ifr_flags = IFF_TUN;
}
If a desired name is given, try that one
otherwise, a default name will be assigned
*/
if(*dev) {
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
Setup TUN/TAP device
*/
if((err = ioctl(tuntap_fd, TUNSETIFF, (void *)&ifr)) < 0) {
perror("ioctl(TUNSETIFF)");
return err;
}
ioctl(TUNSETIFF): Invalid argument
If the system assigns a different name,
copy the name back to the dev name buffer
*/
strcpy(dev, ifr.ifr_name);
}
#ip tuntap add tap0 mode tap
ioctl(TUNSETIFF): Invalid argument
ifconfig tap0 down
ifconfig tap1 down
rmmod -f tun
modprobe tun
printf("DATA: %s\n", buffer);
close(fd);
return err;
Dan
server# socat TUN:172.16.44.1/24,iff-up,tun-name=ssl0,tun-type=tun \OPENSSL-LISTEN:4444,pf=ip4,cipher=HIGH,method=TLSv1,verify=1,cert=selfsign.pem,key=selfsign.key,cafile=selfsign.pem,fork,su=nobody
client# socat TUN:172.16.44.2/24,iff-up,tun-name=ssl0,tun-type=tun \OPENSSL:10.100.1.131:4444,cipher=HIGH,method=TLSv1,verify=1,cert=selfsign.pem,key=selfsign.key,cafile=selfsign.pem,su=nobody
./simpletun -i tun0 -s &
ifconfig tun0 up
ifconfig tun0 add fe80::1234/64
./simpletun -i tun0 -c computer1 &
ifconfig tun0 up
ifconfig tun0 add fe80::5678/64
ping6 -I tun0 fe80::1234
But then run this also on 2 SUSE PCs. On the SUSE PCs the IPv6 pings were transmitted through the tun device,
as it could be seen by wireshark. But the kernel has otherwise ignored the IPv6 pings!
Has anyone an idea, what parameter / compile time configuration pevents the kernel from handling IPv6 packets received at the tun device (but not on eth)?
Juergen
I'm assuming that the basic simpletun IPv4 connection is successful? If the other end's firewall is dropping IPv4 packets, it may look like the peers are connected whereas they are not. Try running simpletun with -d to get debug messages and make sure that the two peers are able to connect successfully.
The SUSE kernel responded to the IPv4 pings but not to the IPv6 pings.
But the SUSE kernel responded to IPv6 pings transmitted through the ethernet device.
I have also tried with an embedded linux 2.6.15 kernel without firewall. There I saw the same behavior.
Therefore I don't believe that this is caused by firewall.
Juergen
1) use tap instead of tun and
2) use non-link-local addresses (eg something in the 2000::/3 range)?
2: I have tried with an fc00:: prefix.
http://www.mail-archive.com/freebsd-net@freebsd.org/msg05969.html
Juergen
Author: Max Krasnyansky
Date: Mon Jul 14 22:18:19 2008 -0700
http://marc.info/?l=linux-netdev&m=121564433018903&w=2
the TUN/TAP driver is seriously broken.
Original patch went in without proper review and ACK. It was broken and
confusing to start with and subsequent patches broke it completely.
To give you an idea of what's broken here are some of the issues:
character device is a network interface in its own right, and that packets
are passed between the two nics. Which is completely wrong.
shortcuts for manipulating state of the tun/tap network interface but
in reality manipulate the state of the TX filter.
got "fixed" and now set the address of the network interface itself. Which
made filter totaly useless.
unnecessary wakeups, filtering is done in the read() call.
Juergen
But kernel 2.6.35 should already contain this bugfix.
-> verify with ifconfig
Or there goes something wrong related to IPv6 neighborhoud discovery or something related.
-> verify with tcpdump
Juergen
As for the buffer filling, if you're talking about writing packets to the pcap output file, as documented in the Wireshark wiki page you only have to write the actual packet bytes in the file, with no padding; but you should also write the correct packet length in the packet header (again refer to that page for the details). However, if you use a library like Jpcap, it should have functions that automatically take care of writing the data to the output file in the correct format; for Jpcap, see for example the writePacket method in the JpcapWriter class. See also the good tutorial on the Jpcap web site.
br,
Saime
Of course, a pcap file is also what you get by default if you run Wireshark directly on the interface while traffic is flowing, and then save it (File -> Save...).
In case you want to write the pcap file yourself, you can use libpcap, which is the low-level library upon which tcpdump, Wireshark and other network analyzers are built. There are some Java wrappers to use libpcap from Java: see for example here and here. Both have tutorial and examples, so you should be able to write your own Java code to capture the packets and save them in pcap format.
http://p2pvpn.org/ A VPN using tun/tap devices written in Java
http://www.koders.com/java/fid6C0CBC76450F649DE9081FE8596BB50FEC023D88.aspx Sample Java code from the P2PVPN application.
/usr/include/linux/if.h:166: error: field 'ifru_dstaddr' has incomplete type
/usr/include/linux/if.h:167: error: field 'ifru_broadaddr' has incomplete type
/usr/include/linux/if.h:168: error: field 'ifru_netmask' has incomplete type
/usr/include/linux/if.h:169: error: field 'ifru_hwaddr' has incomplete type